这是SQL今日一题的第12篇文章
今天有两道题目,因为很相似所以放在一起说。
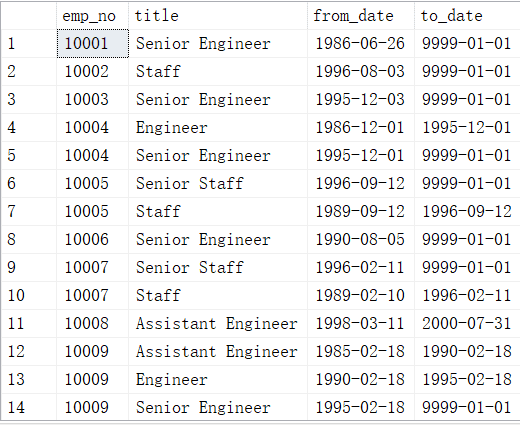
题目描述1从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。
用到titles表,这个表是一个新表,之前的题目没有遇到过,插入如下数据:
select title ,COUNT(title) as t fromtitlesgroup by title having COUNT(title) >=2
题目再解读:要按照title字段分组并计数,结果要筛选出组数大于等于2的,输出title和分组数t,非常简单的分组后再筛选的问题
1、group by按照title分组
2、对title计数,命名为t,从titles表里取出title和t字段
3、分组后筛选,用having进行过滤,选择t大于等于2的记录
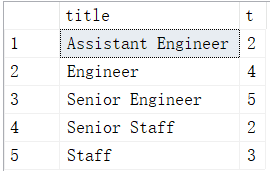
从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。(注意对于重复的emp_no进行忽略(即emp_no重复的title不计算,title对应的数目t不增加)。
方法select title ,COUNT(distinct emp_no) as t fromtitlesgroup by title having COUNT(title) >=2
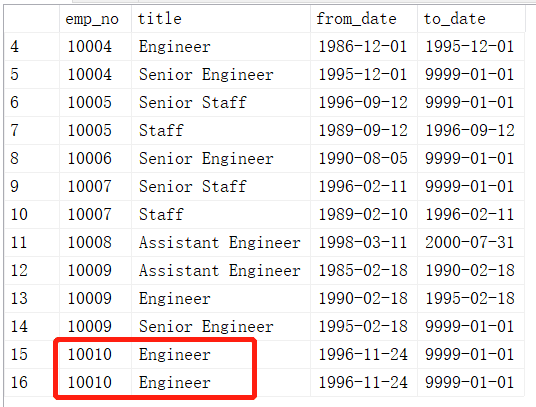
题目再解读:这题和题目1不同的地方在于,这个要对emp_no去重后再计数,意思是如下图所示的emo_no为10010的红框圈出来的两条记录,按照title分组,如按题目1的方法对title计数,则这两条是独立存在的,但按照题目2的要求,对emp_no去重后计数,那么这两条应该被统计为1条结果。
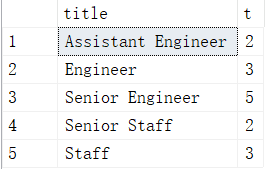
1、group by按照title分组
2、对emp_no去重后再计数,命名为t,取title和t字段
3、分组后筛选,用having进行过滤,选择t大于等于2的记录
可以看到,结果和题目1不同的就在于title为engineer的统计结果。
having
having过滤的是分组,where过滤的是行
having在分组后过滤,where在分组前过滤
count(distinct column)
计算不重复的值出现的次数
先去重,再计数,即先distinct再count
猜你喜欢:
17张思维导图讲清楚统计学
SQL今日一题(11):窗口函数
数学之美:数学究竟是如何被运用到生活中的?
如何做好描述统计分析
数据分析应关注AARRR模型的哪些指标
泰坦尼克号数据分析

以上就是关于SQL今日一题(12):去重后计数什么的微风填词语补充全部的内容,关注我们,带您了解更多相关内容。
